
In this post, I give a somewhat detailed explanation of how stringpool works, touching on some of the design choices I made and challenges I faced. Please note this devlog covers implementation details which are not guaranteed and which may have changed between when I wrote this post and when you are reading it. If you are just trying to use stringpool, please use only its public API1.
Table of Contents
Structures and entities
The main data structure in a pool is a hash map, from which all string data in the pool can be reached. Each key in the map is a hash of a string in the pool, and each value is a list of weak_string_handle which points to a block of string data. A block of string data is called a node.
Nodes
There are three types of nodes, all of which inherit data members from a base node. We define all nodes as packed structs. All nodes are immutable, except their reference counts.
Base node
The base node is not a proper node type, it just represents the set of fields that are shared by all node types. Those fields are:
| Type | Name | Meaning |
|---|---|---|
| size_t | refCount | Reference count of this node. This field is declared only if reference counting is enabled at build time. |
| size_t | hash | Hash of the content of the string represented by this node. |
| pool* | owner | Pointer to the pool to which this node belongs. |
| NodeType (: uint8_t) | type | Indicates the specific type of this node |
Atom node
In addition to the fields from the base node, each atom node consists of simply a 7-byte length followed by the string content. The length is 7 bytes instead of 8 so that it can fit in the same quadword as the 1-byte node type.2
| Type | Name | Meaning |
|---|---|---|
| size_t (7 bytes) | length | Length of the string data. |
Short atom node
Short atom nodes are like atom nodes except they have a 1-byte length instead of 7 bytes. The motivation for this was to avoid wasting bytes on storing the length of short strings. I could have realized more versions of this idea, such as a node type with a 2-byte length, a 3-byte length, etc., but I don’t consider it worthwhile.
| Type | Name | Meaning |
|---|---|---|
| unsigned char | length | Length of the string data. |
Concat node
A concat node represents the concatenation of the strings represented by two other nodes.
| Type | Name | Meaning |
|---|---|---|
| size_t (7 bytes) | length | Length of the (concatenated) string data. |
| node* | left | Pointer to the first string forming the concatenation. |
| node* | right | Pointer to the second string forming the concatenation. |
string_handle
Nodes are not exposed directly to users of stringpool. Instead, users are given string_handles, each of which contains a pointer to a node. A string_handle serves three purposes:
- Point to a node.
- Have user-facing accessor methods that make it possible and convenient to operate on interned string data.
- Manage reference counting (when reference counting is enabled). This includes destroying the node when it its reference count drops to zero.
weak_string_handle
While users of stringpool see string_handle, weak_string_handle is only internal. The difference between the two types is that the weak version does not participate in reference counting. The only place where weak_string_handles occur is in the pool’s hash map. The hash map stores all nodes in a way that lets them be found via a hash lookup, but we do not want this to count toward the reference count of the nodes. If the hash map contained strong references, reference counts would never hit zero (as there is no mechanism for removing things from the map other than the reference count hitting zero), and we would have to delete them when they hit 1 instead. When a new node is created, its reference count would have to be initialized to 2 in order to prevent its immediate deletion. I created weak_string_handle to avoid that awkwardness.
Algorithms
What happens when you call intern?
First, we compute a hash of content of the string argument. We then take a reader lock on the hash map. Note that we compute the hash before taking the lock, because the hash computation is unaffected by the hash map (or any other shared state), and the less time we hold the lock, the better for performance. We then try to find the given string in the map, using the hash as the key. If successful, we make a (strong) string_handle from the weak_string_handle found in the table and return it from intern.
If an equivalent string was not found in the map, we release the reader lock and acquire the writer lock, then check again. If we fail again to find it, we now create a new node and insert it into the map, then return a string_handle to it.
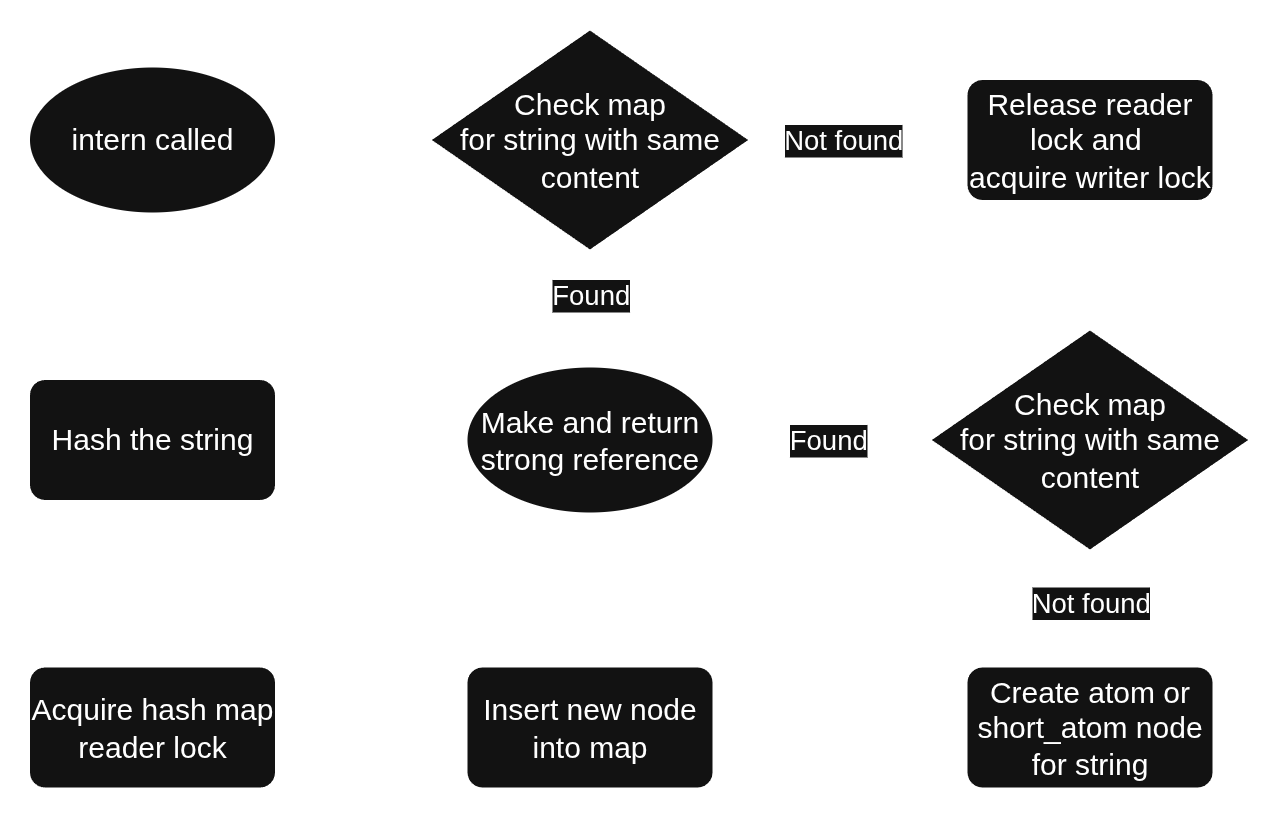
stringpool::pool::internThe reason we search the map again after acquiring the writer lock is that another thread may have inserted our string (or an equivalent one) into the map in between our release of the reader lock and our acquisition of the writer lock. As an alternative to the std::shared_mutex I used, you could use a kind of reader-writer lock that allows upgrading a reader lock to a writer lock without unlocking in between, but I did not, because doing so might not make things as simple as it may seem. In order to avoid potential deadlock, the upgrade operation would likely have to be allowed to fail, at which point you’ve failed to escape needing some sort of retry like we have now.
What happens when you call concat?
concat does mostly all the same things as intern, with the obvious difference that we create a concat node instead of an atom node. A more subtle difference is that, for performance reasons, when computing the hash and checking for equality between existing pool strings, we have to operate on the unrealized result of the concatenation. That is, we have hashing and equality checking code specialized for operating on two string handles as if they were concatenated. (This isn’t too difficult to implement; I just did the same thing as for a single string, but upon reaching the end of the first string, I move to second string.)
A final subtlety when concatenating is that we create a short atom instead of a concat node when doing so saves memory. For example, if we consider code like:
pool p;
auto a = p.intern("Hello, ");
auto b = p.intern("World!");
auto c = p.concat(a, b);A concat node for a + b would be 48 bytes in size, since all concat nodes are that size. (Recall that concat nodes do not contain string data, rather, they contain 2 pointers to other nodes, in this case, the nodes containing “Hello, ” and “World!”.) Meanwhile, the size of a short atom node depends on its payload. In particular, the size of a short atom node is 26 + the length of the string. Therefore, storing “Hello, World!” as a short atom would take up 39 bytes. The short atom cost of 39 is less than the concat cost of 48, so stringpool will make a short atom in this case.
What happens when you call an accessor on string_handle, such as operator==?
Given that a string may be composed of atoms or concats, we have to think of nodes as generally forming a tree. We know the graph will have no cycles because when a concat node (the only kind of internal node) is created, its children must already be in the pool, and because a concat node can be added only as the root of a tree. Given that most strings are short, we can expect most trees to be just a single node, but nevertheless, operations on string content must work by walking the tree in an in-order fashion. For this, I use a stack (std::deque). To avoid the dynamic heap allocations entailed by that, I considered instead having each node contain a pointer to its parent, but I realized that ceases to help as soon as a node has more than one parent, which, in general, will happen. Maybe some more complicated tree-threading3 mechanism could be worthwhile, but I decided to go with the simplicity of the stack approach despite its dynamic allocations. After all, the motivation for this project is trading time for space, and this can be seen as just another example of that tradeoff.
How do char iterators on string_handles work?
string_handle provides an iterator that starts at the beginning and can only move forward, and an iterator that starts at the end and can only move backward. The limitations of these iterators are inherited from my choice to walk the tree in order using a stack, or else in reverse order using a stack. It is certainly possible in theory to make a bidirectional iterator, but it would require more thought and possibly more compute resources for the tree traversal algorithm. I didn’t bother, because it’s fairly rare to need a bidirectional iterator on the chars in a string. Even the reverse one was probably overkill.
What happens when you destroy a string_handle?
In short, destroying a string handle decrements the reference count of the referent node, and if the reference count reaches zero, attempts to delete the node and remove its entry from the pool’s hash map.
There are several pitfalls here that have to be avoided. We use std::atomic_ref::operator-- to atomically both decrement the reference count and know whether the reference count has reached zero. If the reference count reaches zero, we’d like to delete the node and remove it from the hash map. However, the atomicity of decrementing the reference count to zero does not extend to these latter operations. This means that if we’re not careful, something like the following can occur.
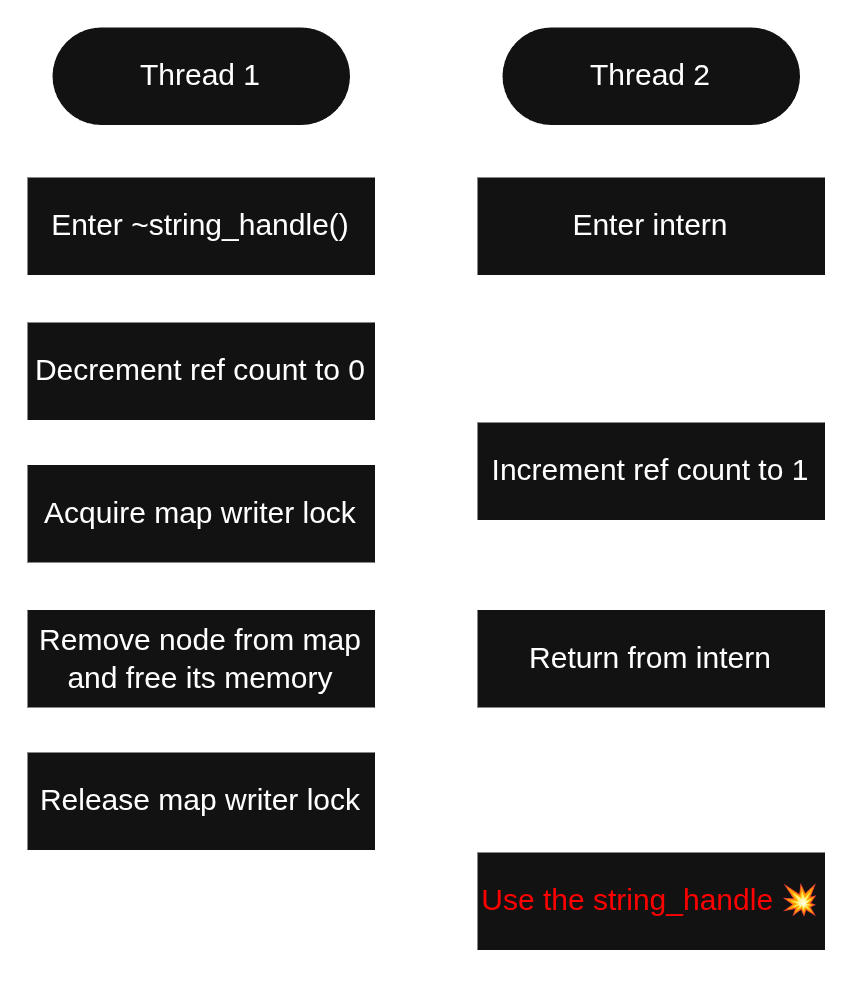
In the scenario shown in Figure 2, Thread 1 decrements the reference count to zero, so it decides to delete the node and free the memory. But during that time, Thread 2 incremented the reference count back up to 1. This could happen if Thread 2 interned a string with the same content as the one that’s about to be deleted. This will cause a use-after-free sooner or later, as Thread 2 now holds a string_handle that points to a node that’s been freed.
I tried to prevent this by rechecking the reference count after acquiring the lock and aborting the deletion if it is no longer zero. This seemed sensible, but it turns out to be insufficient. This is because there are actually three possibilities when a deleter has acquired the map lock.
- The reference count is zero. This is the “normal” case, and it is what would always happen in the single-threaded regime.
- The reference count is greater than zero. This is what happens in the scenario illustrated above, in which another thread increments the reference count for this node by calling
internorconcat. - Another thread has already freed the memory, so trying to read the reference count is a use-after-free.
This third possibility was a blind spot for my design. Although I had intended that only one thread would ever observe the reference count transition from 1 to 0, it is in fact not enforced, and I created tests that show this.
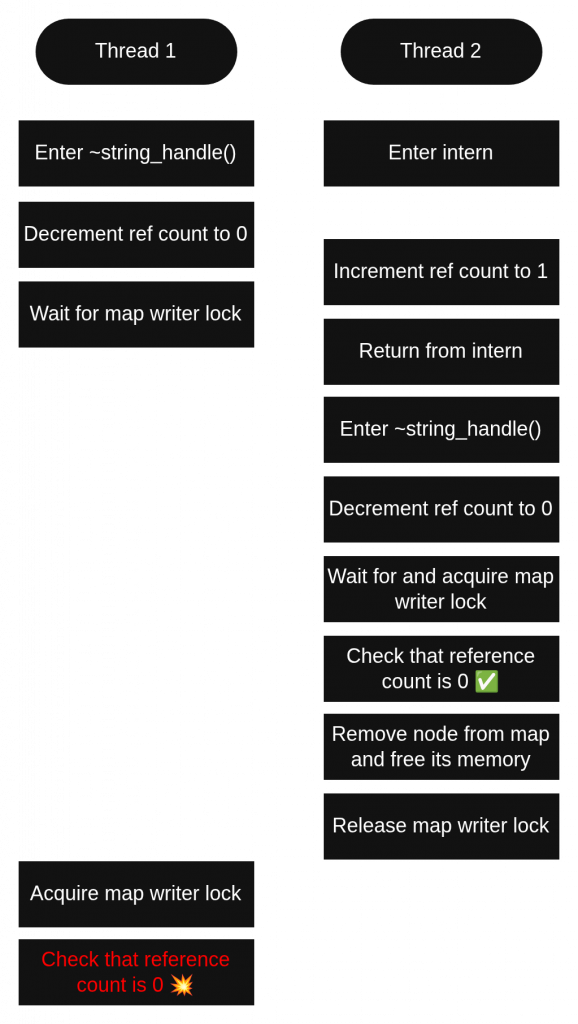
Since checking for whether we lost the race to delete must never involve reading from freed memory, what can we do to detect that situation? The answer I chose is to check the hash map for the node we’re about to delete.4 For this to be safe, we need a few conditions. First, the map must not change concurrently during our check. This is ensured because all sections of code that change a pool’s map hold a writer lock, as do we during this check. Second, we cannot allow our search for the possibly-deleted node to read from the node under any circumstances. This might seem scary, as the map searches done by intern and concat involve comparing string content byte by byte, at least in some cases. Fortunately, the search during deletion needn’t use the actual string content. It suffices to search for the pointer to the node that we are about to delete. In order to find it, we need to know the node’s content hash and the pointer to its owning pool. It is crucial to extract these two fields from the node before decrementing the reference count—otherwise another thread could sabotage our ability to read them.
If the search for the node to be deleted is unsuccessful, we conclude that some other thread already deleted it and simply return without deleting anything. If we do find the node, we check its reference count for zero. This is the same check as before, only this time it’s known to be safe because we just confirmed it’s still in the map, and we still hold the map lock. If the reference count isn’t zero, we don’t delete the node. If it is zero, we can safely delete it without the TOCTOU bug from before, because this time, our possession of the writer lock spans both the zero check and the deletion. The bug mechanism by which other threads obtain references from the map is not available anymore, because they have to hold at least a reader lock in order to access the map, and we’re preventing that by holding the writer lock.
Finally, if the node we’re deleting is a concat node, we decrement the reference counts of its child nodes. We do this regardless of whether the concat node’s reference count is zero. This is a recursive operation, but we don’t bother with recursive locking, since we already hold the only relevant lock.
- The API is discussed in the readme and is defined in the header (the only public types are
poolandstring_handle). ↩︎ - Note that by sacrificing our 8th byte of the length field and making do with 7, we don’t lose practically any ability to represent string lengths. This is because the maximum 7-byte unsigned integer represents a length of 64 petabytes (minus 1 byte), which is well more than any machine today has memory. ↩︎
- See https://www.nist.gov/dads/HTML/threadedtree.html ↩︎
- An alternative answer would be to start holding the mutex before decrementing the reference count, but I expect that would carry a huge performance cost, as reference counts go up and down more than you’d think, even in simple code with short-lived strings. In the design I chose, the string_handle destructor grabs the mutex only when it sees the reference count hit zero, which is far from every time it runs. ↩︎